
适用于
分类(旧)
OCR更多信息
| 分享时间 | 2022-10-18 22:51 |
| 最后更新 | 2024-06-07 22:37 |
| 修订版本 | 34 |
| 用户许可 | -未设置- |
| Quicker版本 | 1.42.43 |
| 动作大小 | 216.2 KB |
| 最低Quicker版本 | 1.36.7 |
简介
1. 使用前提:
安装quicker浏览器拓展。如下图:

2. 使用说明
程序将自动获取白描网页版的登录信息(基于quicker浏览器拓展)。如果之前在浏览器中登录过,本动作将会在第一次运行时自动打开白面网页版,第二次运行时获取参数(是的,在第一次弹出的网页上登录后,请直接再运行一次动作捕获登录信息),之后运行不再需要弹窗;如果之前没有登陆过白描网页版,那么请先登录网页版再运行本动作,或者在动作打开的浏览器中登录白描账号。
3. 数据说明
登录信息通过缓存保存在本机,参考文档。
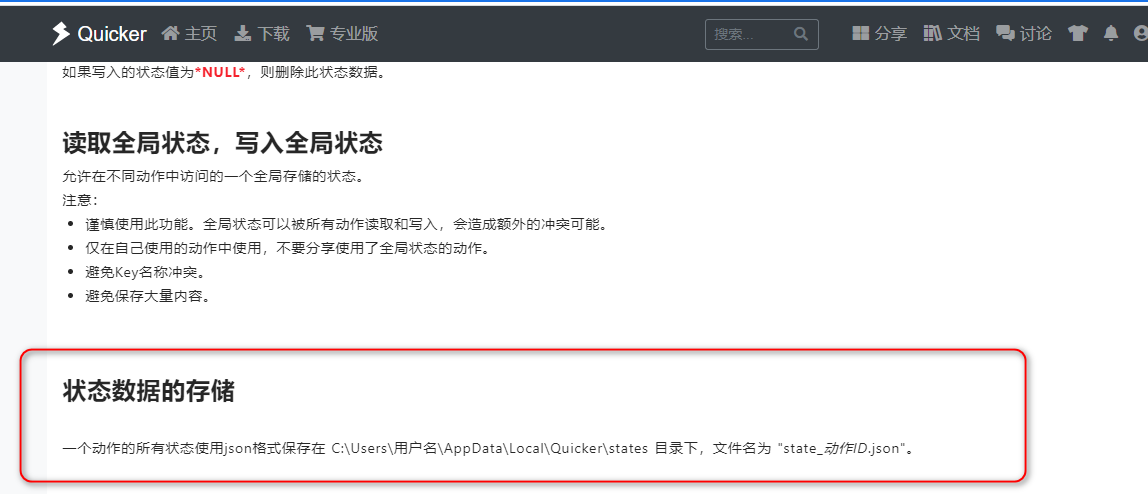
如果需要删除/同步登录信息,请根据上图删除/同步对应的json文件。
或者根据文档,按以下方式删除
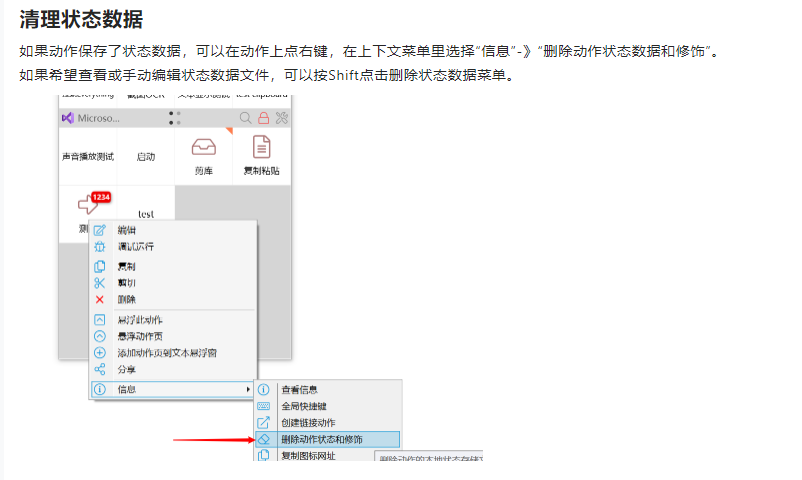
4. 修改说明
基于https://getquicker.net/Sharedaction?code=117abe7e-2396-4620-713a-08da09549333修改:
1. 增加了自动登录
2. 去除了结果弹窗,只自动复制到剪切板结果仍然弹窗,不需要的请停用最后一个操作。
3. 修复现有图片识别时,出现“变量不是位图文件”的报错的bug。
4. 改进了请求参数hash的生成方式,现在请求参数和网页版完全一样了,应该不会再出现获取不到结果的情况。如有,请反馈。
5. 取消了过程中的参数弹窗,只显示最后获取识别结果成功与否。
6. 增加了右键菜单。识别结果弹窗请在右键菜单中点击启用/关闭。
7. 根据白描网页版增加了表格识别(已完善),公式识别(无法渲染成网页版的结果,半成品已解决),pdf转word(未完善,暂时无法使用)。直接点击动作图标,默认执行图片文字识别(该默认项无法更改),如果需要使用其他识别类型,请对白描ocr动作图标点击右键,在右键菜单--->“全部识别类型”中单次选用。
当前各种识别类型说明:
图片文本识别:图片--->txt
数学公式识别:图片--->txt
电子表格识别:图片--->xlsx
pdf转word:pdf--->docx(暂不可用)
8. 增加了 图片文字提取结果处理为富文本(html)的功能,以保留缩进等格式。
9. 修正了服务器可能会使用不同识别引擎,而脚本没有适配的bug。如果弹窗出了新的引擎,请向我反馈。
10. 修复了部分请求编码的问题,不出意外应该有助于解决识别为空的问题。
11. 增加了默认识别类型设置。默认识别类型将在动作徽标上以红底白字显示。
12. 增加了excel文本识别是否默认打开下载的excel文件的设置。在右键菜单---电子表格识别---自动打开识别结果 启用或者关闭。
12+1. 增加了仅保留文本的功能,也就是富文本去除标记符,保留分段的效果。
14. 修复了公式识别结果。默认为latex格式,需要其他格式的朋友请去https://www.latexlive.com/网站转换。
15. 修复了一处菜单设置不合理,导致无法单次使用excel识别的问题。
16. pdf识别功能正式上线。注意:首次使用会自动下载两个小工具。识别过程中会临时导出pdf每页的图片,默认保存在文档>quicker文件夹下,生成的临时图片文件在识别完成后会自动删除。
识别结果会保存为word文件,默认下载到和原pdf同一文件夹下,文件名一样,如果有同名文件,会强制覆盖。
word识别结果默认自动打开,改功能可在设置中关闭。
17.pdf识别增加了进度条。
18.识别窗口增加了简繁转换功能。
19. 根据白描网页端的变化,增加了对baidu识别引擎的支持。
提醒:pdf转文字1次最多识别50页,这是白描网页版的限制!!!因此本次更新增加了识别弹窗提醒,在超过50页的pdf进行识别时,将只会识别前50页。5. TODO
过滤选中文件中的非图片文件,避免出现“变量不是位图文件”的报错。
检测到登录失效后清空登录状态,第二次运行即可自动重新获取。当前由于qicker缓存机制,无法在停止时更新缓存状态。其他可行方案我再想想。(应该解决了,不行请反馈)
增加右键菜单,实现表格识别和pdf识别。
增加图片识别下载为word功能,以保留段落缩进。用富文本实现了
- 重构,目前的代码太乱了。
6. 调试运行
如果使用中出现了bug,你想要帮助改进/修复这个动作,请参照官方调试指引,上传你出现问题时的日志。
注意:因为日志中含有你的登录cookie信息,在问题解决后,请务必去白描手机版取消白描对本动作的登录授权(如果你不知道哪个是本动作对应的登录记录,我建议你全部取消授权),然后再使用本动作重新登录,以保护你的隐私。
最近更新
| 修订版本 | 更新时间 | 更新说明 |
|---|---|---|
| 34 | 2024-06-07 22:37 | 1. 增加了在特殊情况下,获取识别结果的等待时间。应该有助于获取不到识别结果的解决 |
| 33 | 2024-06-07 22:32 | 1. 增加了在特殊情况下,获取识别结果的等待时间。应该有助于获取不到识别结果的解决。 |
| 32 | 2024-05-23 22:46 |
1. 修复了baidu识别引擎在打开保留结果格式时的出错。
注意:白描貌似修改了之前两个识别引擎的结果结构,但是我没有复现出来,因此没有处理。如果遇到了错误,请上传错误日志,帮助定位修复。 |

 京公网安备 11010502053266号
京公网安备 11010502053266号