适用于
分类(旧)
文本处理 功能增强关键词
更多信息
| 分享时间 | 2022-04-30 21:28 |
| 最后更新 | 2024-04-23 15:19 |
| 修订版本 | 19 |
| 用户许可 | -未设置- |
| Quicker版本 | 1.42.32 |
| 动作大小 | 229.5 KB |
简介
若需要「操作窗」版本,可通过这个动作实现 超级操作窗
💡 视频介绍
限于视频体积,请移步B站 点这里
💡 基础操作
处理选中文本
选中文本 → 运行动作 → 选择替换规则 / 手动输入替换规则
文件批处理
选中文件 → 运行动作 → 选择替换规则 / 手动输入替换规则
文件批处理,默认输入文件的编码为 UTF-8 ,可动作右键菜单「偏好选项」改为 非UTF-8 。
使用界面
动作有3种使用界面:
- 查找替换
- 规则库(用户选择)
- 规则库(显示菜单)
可在设置中指定默认的使用界面。此外,还有另一种指定方式,通过轮盘菜单、扩展热键、鼠标手势等方式启动时,附加对应的参数:
- 查找替换
- 用户选择
- 显示菜单
💡 小白使用指南
替换规则是以正则表达式为基础的,作为小白的我可以多大程度上使用动作?
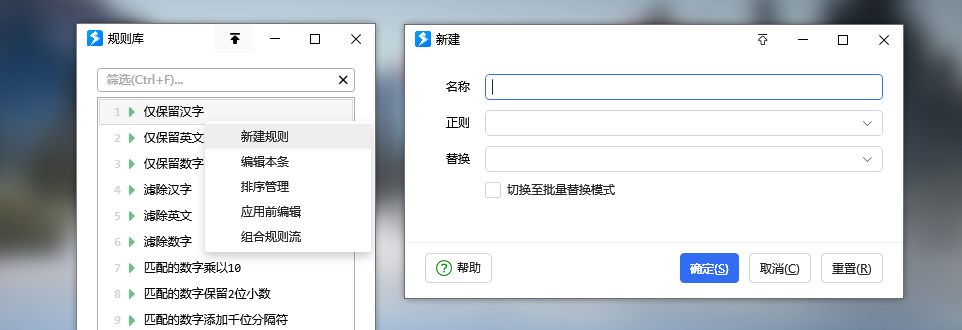
1. 使用现成的替换规则库。动作预置了尽可能多的替换规则,开箱即用。以后如果有添加,会更新到动作右键菜单的「规则参考」里面。
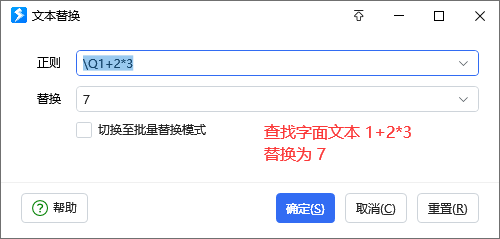
2. 不是所有替换需求都需要用到正则替换的,如果我希望用普通替换创建规则,怎么操作呢?在正则框输入要查找的文本,开头加上 \Q, 就是普通的查找替换了。(同样适用于批量替换模式,示例写法 \Q1+2*3|7)
3. 规则库里的不少规则是模板性质的,只要稍作修改就能符合具体需求,并不要求掌握正则表达式或C#语法。比如规则 “匹配的数字乘以10”、“匹配的数字保留2位小数”、“每行文本添加前缀”、“保留字数>20的文本行” 等等,猜猜改改。

4. 如果你的需求可以由规则库现成的规则组成,那么你可以自由组合已有规则,创建一条相对复杂的规则流。
例如,把以下的规则组合成一条新的规则:一键排版。
去除每行前后空白 → 合并断行 → 删除空白行 → 段首缩进2字符 → 隔行插入空行
5. 最后的最后,如果不会写规则,欢迎在动作讨论区留言交流。
💡 快速参考
正则选项
如需启用正则选项,请使用内联修饰符:
| 正则选项 | 内联字符 |
|---|---|
| IgnoreCase 忽略大小写 | i |
| Singleline 单行模式 | s |
| Multiline 多行模式 | m |
示例:(?is)abc 表示正则表达式 abc 启用“忽略大小写”和“单行模式”。
替换表达式
$= 启用替换表达式
$& 代表整个正则的匹配文本
$1 代表正则第一个捕获组的匹配文本
$# 代表匹配项的序号(始于1)
示例1:
把匹配结果转换为大写
正则:\w+
替换:$= $&.ToUpper()
示例2:
每行文本添加序号
正则:(?m)^
替换:$= $# + "."
示例3:
将文本中的数字转换为中文
正则:\d+
替换:$= num2cn($&)
| 函数 | 说明 | 示例 | 结果 |
|---|---|---|---|
| cn2num | 中文转数字 | cn2num(“一九零六”) | 1906 |
| num2cn | 数字转中文 | num2cn("1906") | 一千九百零六 |
| num2formal | 数字转大写 | num2formal("1906") | 壹仟玖佰零陆元整 |
| num2simple | 数字转简读 | num2simple("1906") | 一九〇六 |
批量替换
每行一对查找和替换内容。中间使用|或|||分隔。例如将a替换成A,写作:a|A 或 a|||A
批量替换同样支持替换表达式
实际上动作采用 ◒◒◒ 作为分隔符,竖线会自动转换为 ◒◒◒ 保存。
允许竖线是为了方便书写,并且和 Quicker 语法保持一致。
正则语法
.NET 正则快速参考
动作专门为中文环境自定义了一系列正则语法:
| 语法 | 匹配 | 说明及示例 |
|---|---|---|
| \o | 几乎任何字符 | 匹配除了 \r , \n 以外的任何字符。示例,每行插入前后缀: 【源文本】“123\r\n456" 【正 则】\o+ 【替换为】前$&后 【结果文本】“前123后\r\n前456后” |
| \O | 任何字符 | 匹配包括 \r, \n 在内的任何字符,等同于“单行模式”下的点号 . |
| \e | 英文字母 | 匹配任意英文字母,等价于 [a-zA-Z] |
| \E | ASCII字符 | 匹配任意ASCII字符。示例,提取英文句子: 【源文本】hello, world! 你好,世界! 【正 则】\E+ 【匹配结果】hello, world! |
| \h | 汉字 | 匹配任意汉字(Unicode基本平面) |
| \H | 非ASCII字符 | 匹配任意非ASCII字符。示例,提取中文句子: 【源文本】hello, world! 你好,世界! 【正 则】\H+ 【匹配结果】你好,世界! |
| \c | 中文小写数字 | 等价于 [〇一二三四五六七八九十百千万亿兆] ,示例: 【源文本】第五十八回 潘金莲打狗伤人 孟玉楼周贫磨镜 【正 则】第\c+回 【匹配结果】第五十八回 |
| \C | 中文大写数字 | 等价于 [零壹贰叁肆伍陆柒捌玖拾佰仟亿兆] ,示例: 【源文本】人民币壹仟陆佰捌拾元整 【正 则】\C+ 【匹配结果】壹仟陆佰捌拾 |
| \; | 类型边界 | 匹配字母串、数字串、汉字串的开头或结尾。示例,匹配没有包含在数字串里面的数字: 【源文本】20220122 第22天共220小时 【正 则】\;22 【匹配结果】匹配到第三个和第四个22 【正 则】\;22\; 【匹配结果】只能匹配到第三个22 |
| \< | 行首 | 匹配每行的开始处,即字符串的开头或 \r\n , \r , \n 之后的位置 |
| \> | 行尾 | 匹配每行的结尾处,即字符串的末尾或 \r\n , \r , \n 之前的位置 |
| \Q | 普通匹配 | 放在正则表达式的最开头,消除所有元字符的特殊含义 \Q1+2*3 等同于 1\+2\*3 |
最近更新
| 修订版本 | 更新时间 | 更新说明 |
|---|---|---|
| 19 | 2024-04-23 15:19 | - 添加一系列「单元格文本处理」及「中文数字转换」规则 |
| 18 | 2024-04-22 12:46 | - 替换表达式中支持中文数字转换 |
| 17 | 2024-04-17 00:47 |
- 优化选中判断,提升动作启动速度
- 优化批处理进度条,显示当前文件名 |

 京公网安备 11010502053266号
京公网安备 11010502053266号