提取一个统计网站,每天都会更新数据。 使用【提取HTML内容】功能,的确可以提取到内容,但是,第二天源站更新之后,提取的依然是昨天的数据,我怀疑是有缓存,但是不知道在哪里清除,求支招
右键图标删除动作数据再运行试试
不能每次运行都删除重新弄呀,而且也试过删除了,重新建立的话,还是会有缓存
如果删除动作数据能获取今天的数据,说明这动作是可以实现每次都获取今天的数据的
现在是有个猜想,就是【提取HTML内容】功能调用了默认浏览器的某个啥,然后缓存的内容实际是默认浏览器里面
GET请求可能会被缓存。可以先使用http请求得到内容后再使用提取模块提取。 或者请求的网址里增加一个随机参数。
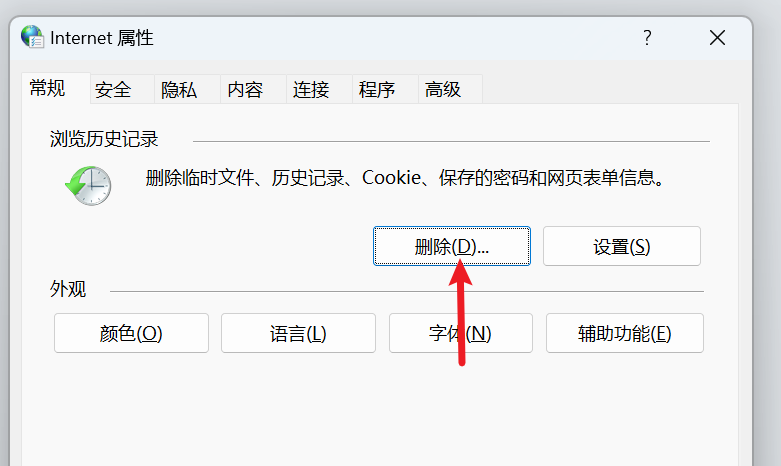
这个缓存在哪里呢,该怎么清除
手动清理很麻烦,建议在网址中添加一个变化的额外参数(如时间戳或随机数)

 京公网安备 11010502053266号
京公网安备 11010502053266号