能否添加主要演员和IMDb?自己尝试添加失败,麻烦作者了
功能建议
·
690 次浏览
liuyun198833
创建于 2022-04-02 09:21
1、添加主演,如截图所示,不知道怎么处理了。


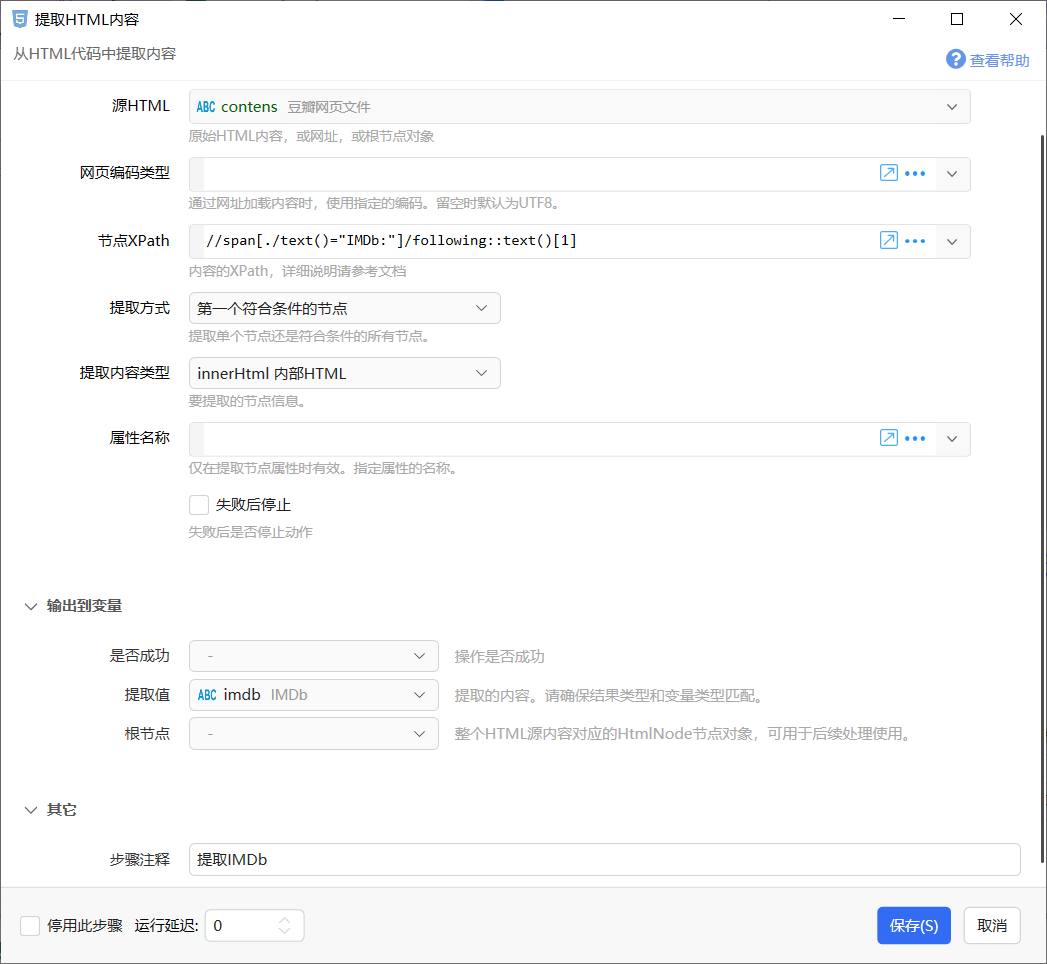
2、添加IMDb,xpath显示能获取到IMDb,但运行时获取到的不是截图中的IMDb编号,而是\n\n,会不会与IMDb号以tt开头有关。


回复
请绑定手机号后发表评论



 京公网安备 11010502053266号
京公网安备 11010502053266号